The House of Representatives wants to improve how the Statements of Disbursements are published as data and they are asking for your help and input. A summary of how we got to this point is immediately below. Skip to the bottom if you want to share your views on how the Statements of Disbursements should be published, including reviewing a sample data set that contains the House’s proposal as well as a link to where you can provide feedback.
A Brief Explanation of How We Got Here
As you know, the House’s Statements of Disbursements contain a quarterly accounting of all expenditures in the House of Representatives. Initially published only as a print document, in recent years they’ve been published online as PDFs and now as spreadsheet files (CSVs.)
The spreadsheet files, however, do not contain a public-facing unique identifier for some of the entities and also do not include some potentially useful metadata. For example, they do not contain a unique identifier for each congressional office that spends funds. They do not contain a unique identifier for the recipients of the funds, whether it is an entity (like Lockheed Martin) or an individual (e.g. staffer ‘John Jameson.”) They do not include a categorization (a budget code) for the various kinds of spending.
The absence of a public-facing unique identifier for the recipient can make it difficult to analyze the data.
- Entity recipients, like Lockheed Martin, can be represented in several different ways in the same data file, so if you want to see all expenditures for Lockheed Martin, you have to resolve the various ways that the business is represented in the text.
- Individual recipients, like staffers, can also be difficult to track. The names are displayed inconsistently over multiple statements of disbursements, so if you wish to see money received by an individual over the course of a year, that can be hard to do without dealing with the variations of the persons name. In addition, sometimes you have multiple individuals with the same name and there’s no obvious way to disaggregate them.
Pursuant to House direction, the Chief Administrative Officer has proposed an improved way to publish the data to include the metadata. In my view:
- It does a good job of making it possible to identify the entities spending the money by providing unique identifiers for the various offices (This is the new field “Organization Code”)
- It does a good job of categorizing the kinds of spending, so you can use the federal government’s budget codes to count the amount of spending per category. (This is in the new “Budget Object Classification” and “Budget Object Code” fields)
- It does a good job of consolidating identifiers for entities that receive spending, so you can see, for example, all the spending on Lockheed Martin in its various incarnations. (This is in the new “Vendor ID field”)
- It does not, however, address a key concern with respect to uniquely identifying staffers. This means that you cannot distinguish between staffers with identical/similar names and you cannot track a staffer over multiple statements of expenditures. In my view, the House should publish a public-facing unique ID for each staffer (but obviously not publish the pre-existing internal ID). This will allow for better tracking of staff pay rates, turnover, building congressional staff directories, and so on. (This information is not contained in the new “Vendor ID” field, but in my view, should be)
The House Chief Administrative Office gave a presentation at the September 29th Congressional Data Task Force and asked for your feedback. Video is not yet available online, but we have a recap here and you can view the slides from the CAO presentation here.
How to provide your feedback
The House CAO published on the Legislative Branch Innovation Hub links to:
- slides from their presentation,
- a sample spreadsheet of what the SOD would look like, and
- a link to submit feedback on their GitHub Page.
Please note that these links will immediately download the PowerPoint file, the spreadsheet, and send you to their github page.
Slide #4 generally explains what they intend to do.

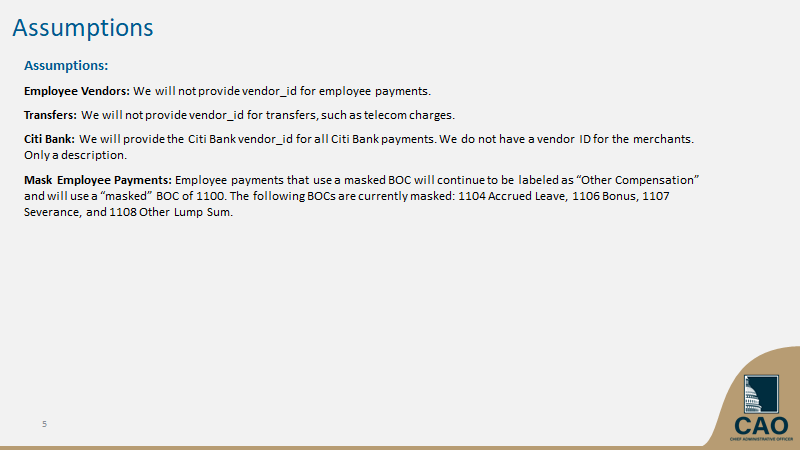
Slide #5 explains some of their assumptions for information they would still withhold for privacy or other purposes.
To make this make sense, you may wish to download the sample CSV. I’ve included a snippet below.

But the most important step is to provide your feedback. You can do that here.
My advice on how to give feedback: the House is under no obligation to make any of these changes. It is great that they are improving how they publish the Statement of Disbursements and it is phenomenal that they are asking for public feedback. When providing your comments, it’s important to say the changes that you like, to express appreciation for their efforts, and if there are improvements that you’d like to see, to be clear in indicating what you’d like to see.
I think the proposal largely addresses our concerns with the sole exception of ensuring accurate identification of staffers. Private services are already doing the hard work of disambiguating staffers, and it’s important to make sure that they can do so correctly (i.e. without error) while also empowering others to more easily make these distinctions. This will support better analysis of trends in staff pay over time, the construction of staff directories, and so on.